Summary of paper on RAID survey
- Summary of paper on RAID survey
Abstract
- disk arrays
- to use parallelism b/w disks to improve I/O performance
- intro to disk technologies
- need for disk arrays
- performance
- reliability
- techniques used in disk arrays
- striping
- improves performance
- redundancy
- improves reliability
- striping
- description of disk array architectures (RAID 0-6)
- refining RAID levels to improve performance and designing algos to maintain consistency
Introduction
- RAID
- Redundant Array of Inexpensive(or Independent) Disks
- driving force?
- performance and density of semiconductors is improving
- faster microprocessors, larger primary memory
- need larger, and high performant secondary storage
- Amdahl’s law
- large improvements in microprocessors, still less improvements overall unless secondary storage improves
- disc access times improve < 10%/year, mup performance > 50%/year
- disc transfer rates ~ 20%/year
- performance gap is widening
- large improvements in microprocessors, still less improvements overall unless secondary storage improves
- data intensive applns bulding up daily
- image processing
- video, hypertext, multimedia
- high performance n/w based storage systems are required
Disk Arrays
- stripe data across multiple disks
- access in parallel
- high data transfer rate on large data access
- high I/O rate on small data access
- uniform load balancing
- Problem?
- disk failures
- n disks => n times more likely to fail
- Mean Time to Failure(MTTF) of x hrs for a disk means MTTF of x/n for a n disk array
- Solution?
- redundancy
- error correcting codes
- Problems?
- write operation => write to all redundant parts too
- so, write performance decreases
- maintaining consistency in concurrent operations and system crashes
- Problems?
- Various striping and redundancy techniques
- each have some trade-offs among reliability, performance and cost
Background
Disk Terminology
- platter
- coated with magnetic medium
- rotates at constant angular velocity
- disk arms with magnetic r/w heads that move radially across platter’s surfaces by an actuator
- once positioned, data is r/w in small arcs called sectors on platter and platter rotate relative to heads
- although all heads move collectively, only one can read at a time
- a complete circular swath is called track
- vertical collection of tracks at a radial position is called cylinder
- Disk service time consists of
- seek time
- to move head to correct radial position, ranges from 1 to 30ms
- rotational latency
- to bring desired sector under head, ranges from 8 to 28ms
- data transfer time
- depends on rate at which data can be transferred from/to platter’s surface
- depends upon rate of rotation, density of magnetic media, radial distance of head from center
- zone bit recording can be used to store more data on outside tracks
- ranges from 1 to 5 mb/sec
- seek time + rotational latency = head-positioning time
- seek time
- Total time depends upon the layout of data as well
- if it is laid sequentially within a single cylinder, vs
- if it is laid randomly in say 8kb blocks
- so, I/O intensive applications are categorized as
- high data rate - minimal head posiitoning via large, seq accesses
- eg scientific programs with large arrays
- high I/O rate - lots of head positioning via small, more random accesses
- eg transaction processing programs
- high data rate - minimal head posiitoning via large, seq accesses
Data paths
- information stored on platter in form of magnetic fields
- it is sensed and digitized into pulses
- pulses are decoded to separate data bits from timing-related flux
- bits aligned into bytes, error-correcting codes applied and extracted data delivered to host as data blocks over peripheral bus interface such as SCSI (Small Computer Standard Interface)
- these steps are performed by on-disk controllers
- the peripheral bus interfaces also include mapping from logical block number to actual cylinder,sector,track
- this allows to avoid bad areas of disk by remapping bad logical blocks
- topologies and devices on path b/w disk and host vary depending on size and type of I/O system
- channel path consists of
- channel
- storage director
- head of string(collection of disks that share same pathway)
- channel processor is aka I/O controller or Host Bus Adapter (HBA)
- from HBA, data is transferred via direct memory access over a system bus to host OS buffers
- channel path consists of
Technology trend
- recording density is increasing
- allows capacity to stay constant or increase when size is decreasing
- with increase in rotational speed, transfer rate also increases
Disk Array Basics
Striping and Redundancy
- Striping
- distributes data over multiple disks to make them appear as single fast, large disk
- multiple independent requests could be serviced in parallel by separate disks => queuing time decreases
- single multi-block requests can be serviced by multiple requests in coordination => effective transfer rate increases
- More the # of disks, better the performance, but larger # of disks decrease reliability
- distributes data over multiple disks to make them appear as single fast, large disk
- Redundant Disk array organizations can be distinguished on basis of
- granularity of data interleaving
- fine grained
- interleave data in small units
- all I/O reqs access all disks in disk array
- high data transfer rates but
- only 1 logical I/O request can be serviced at a time
- all disks must waste time positioning for evry request
- coarse grained
- interleave in large units
- small request use less disks so multiple can be served
- large request use all disks so high transfer rate
- fine grained
- how redundant information is computed and distributed
- granularity of data interleaving
- How to compute redundant information
- parity
- hamming code
- reed-solomon code
- how to distribute redundant information
- 2 patterns
- concentrate redundant information on small # of disks
- distribute the information across all disks
- desirable
- load-balancing prob avoided
- 2 patterns
Basic RAID Organizations
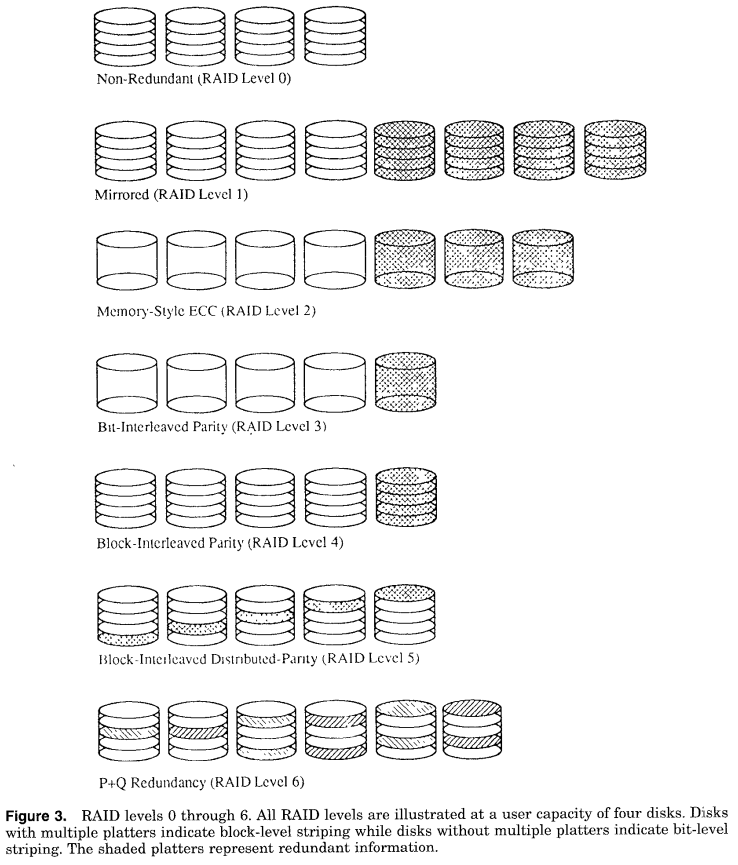
Nonredundant - RAID Level 0
- lowest cost
- no redundancy
- best write performance
- read performance is not better
- redundant disks could do better by scheduling reqs on disks with shortest expected seek and rotational delays
- single disk failure => data loss
- used in supercomputing environments where performance and capacity is preferred over reliability
Mirrored - Level 1
- mirroring or shadowing
- use 2x #disks
- write is done on both set
- read can be done from one with shorter queing,seek,and rotatinal delays
- usage in database applications
Memory-Style ECC - Level 2
- much less cost than mirroring
- uses Hamming codes
- number of redundant disks is proportional to log of total nuber of disks
- when a disk fails, several of parity components will have inconsistent values and failed is the one held in common by each incorrect subset
- lost information is recovered by reading other components in subset including parity component
Bit interleaved parity - level 3
- single parity disk to recover lost information
- data is conceptually interleaved bit-wise over data disks
- and there is single parity disk
- a read request accesses all data disks
- write request accesses all data + parity disks
- so only 1 request can be serviced at a time
- parity disk contain no data so cannot participate in reads
- user for high bandwidth but nor I/O rates
Block interleaved parity - Level 4
- data is interleaved in blocks of arbitrary size
- size is called striping unit
- read request < striping unit access only 1 data disk
- write request must update parity and data blocks
- if write uses all disk then parity is just xor of all
- a small write(on ledss than all disks) requires 4 disk I/O
- write new data
- read old data
- read old parity
- write new parity
- parity disk can be a bottleneck since it is used in every write request
Block interleaved distributed parity - level 5
- distributes parity uniformly over all disks
- all disks participate in read
- have best small read, large read, large write performances
- small write reqs are inefficient due to 4 I/O reqd
- how u distribute parity can affect performance
- best was left symmetric case
- universally preferred over level 4
P+Q redundancy - level 6
- uses reed solomon codes to protect 2 disk failures
- uses 2 redundant disks
- similar to block interleaved structurally
- small writes require 6 disk I/Os
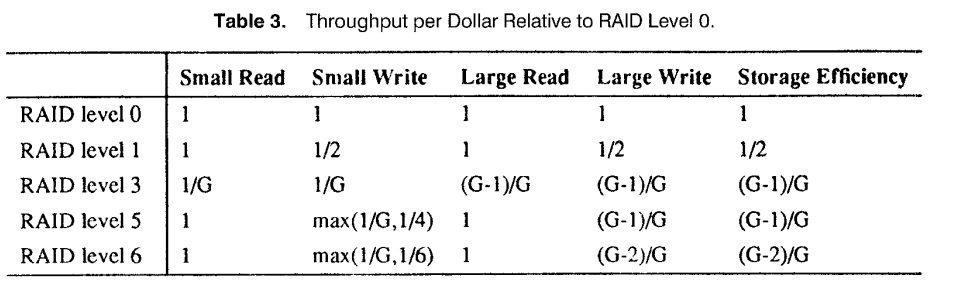
Performance and Cost comparisons
- metrics to evaluate disk arrays
- reliability
- performance
- #io per second
- cost
- generally aggregate throughput is more important than response time on individual requests
- normalize metrics i.e. intead of #io/second, take #io/second/dollar
- compare systems with equivalent file capacities (amount of information that can be stored apart from redundant information storage)
Reliability
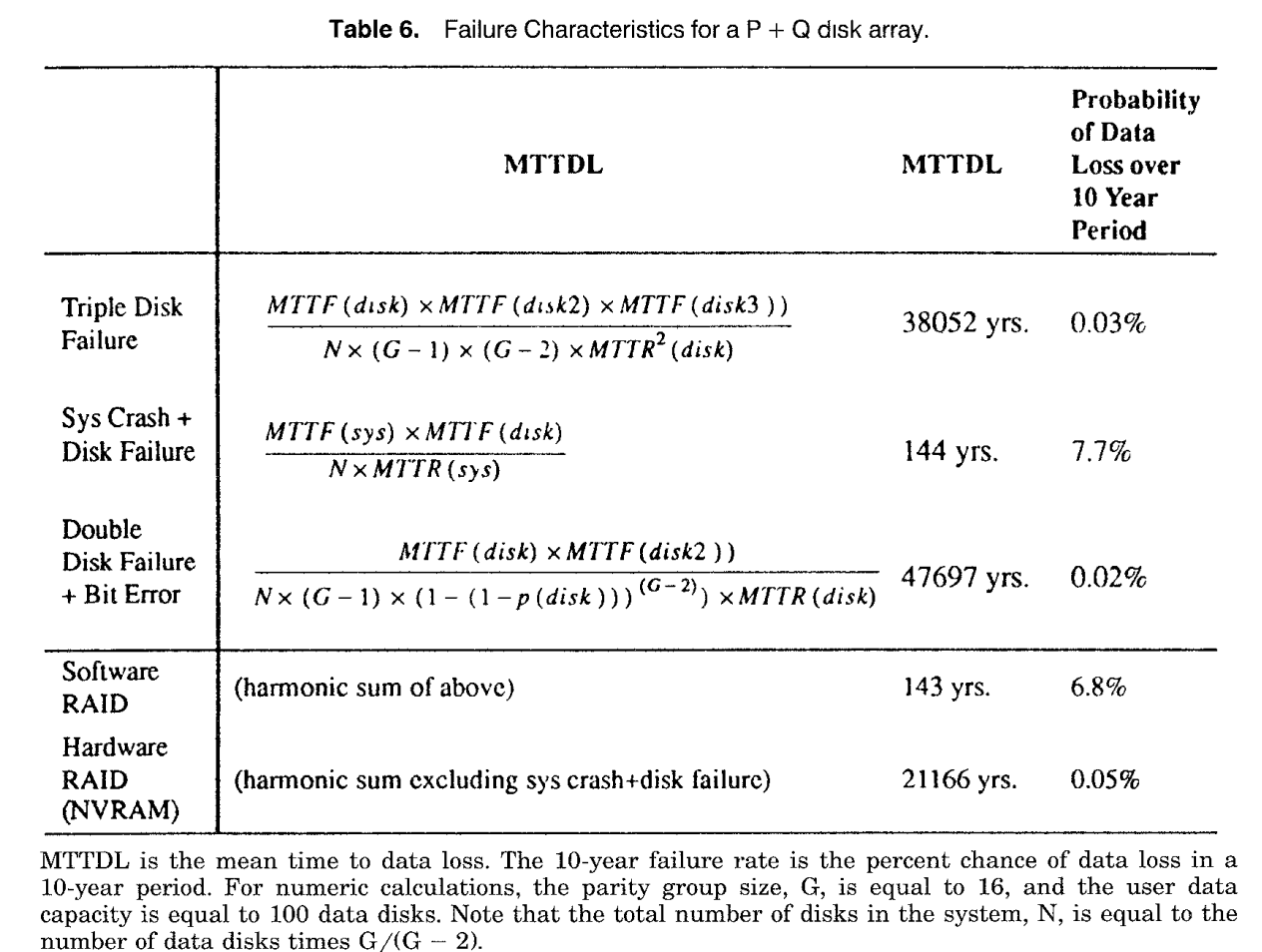
- if only independent disk failures are considered, MTTF for RAID level 5 is
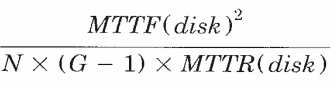
- MTTF and MTTR are mean time to failure and repair for one disk
- N is number of disks
- and G is parity group size
- 100 disks, each with MTTF = 200k hrs, and MTTR = 1hr, with G = 16 => MTTF = 3000yrs
- For disk array with 2 redundant disk per parity group such as P+Q have MTTF as
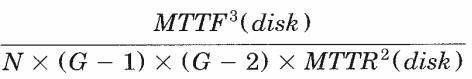
- using same values => 38 mn yrs
- factors like system crashes, uncorrectable bit errors, correlated disk failures can affect reliability a lot
System Crashes and Parity Inconsistency
- System crash = power failure or s/w crash or h/w breakdown etc
- can lead to inconsistent states
- parity updated, data not and vice versa
- use redundant h/w ? still 100% reliability can’t be achieved
- bit interleaved and block interleaved both have this prob but latter is of concern
- because it can change parity of data that wasn’t being written
- so system crash is equivalent to disk failure
- also, system crashes occur more frequently and in P+Q type => 2 disk failures?
- solution?
- logging of data to non-volatile storage before writing
Uncorrectable Bit Errors
- fail to read/write small bits of data
- generated because data is incorrectly written or gradually damaged as magnetic media ages
- when constructing a failed disk by reading data from unfailed disks, assuming a bit error rate of 1 in 10^14 => success prob is 99.2% => 0.8% times you could not recover it due to uncorrectable bit errors
Correlated Disk Failures
- environmental and manufacturing factors can cause correlated disk failures frequently
-
earthquake, power surges, power failures etc
- three modes for failure for raid 5
- double disk failure
- system crash followed by a disk failure
- disk failure followed by an uncorrectable bit error during reconstruction.
Failure Characteristics for Level 5 and P+Q RAID types

Implementation Considerations
- Disk array state information contains of data and parity information, and apart from that
- it also contains information like which disks are failed, how much of a failed disk has been reconstructed, which sectors are currently being updated (because these information are reqd when system crashes)
- this information is known as metastate information
Avoiding Stale data
- need to maintain information about validity of each sector of data and parity in disk array
- when a disk fails, marks its logical sectors invalid (prevents corrupted data read)
- when invalid sector is reconstructed, mark it valid (ensures new writes update the information on this sector)
- maintain vailid/invalid information as bit vector
- updating valid/invalid metastate information to stable storage does not present significant performance overhead
Regenerating Parity after System Crash
- information about consistent/inconsistent parity sectors is required to be logged to a stable storage to avoid regeneration of all parity sectors in case of a failure
- before performing write, mark parity sectors as inconsistent
- and after bringning a system up from system crash, regenerate all inconsistent marked parity sectors
- and periodically these sectors should be marked as consistent
- performance prob in S/W RAID systems since they do not have access to fast non volatile storage
- methods to implement
- mark parity sector inconsistent b4 every write
- keep a MRU pool of inconsistent parity sectors in memory to avoid remarking of already marked inconsistent sectors
- this works if there is a large locality of reference
- in transaction processes, large # of random write reqs, use group commit mechanism, a large # od parity sectors can be marked inconsistent with single access to non-volatile storage
- improves throughput but results in higher latencies for some writes
Operating with failed disks
- system crash in block-interleaved is similar to disk failure (it can result in loss of parity info)
- some logging is reqd on every write to prevent loss of information in case of system crash
- 2 ways to do so
- demand reconstruction
- requires stand-by spare disks
- access to parity stripe with invalid sector trigger reconstruction of appropriate data immediately to a spare disk
- write ops never deal with invalid sectors created by disk failures
- parity sparing
- no stand-by spares reqd
- request additional metastate information
- b4 servicing a write request to invalid sector parity stripe, sector is reconstructed and relocated to overwrite its corresponding parity sector
- and sector is marked as relocated
- when failed sisk is replaced
- relocated sector is copied to spare disk
- parity is regenerated
- sector is no longer marked as relocated
- demand reconstruction
Advanced Topics
Improving Small Write Performance on RAID level 5
- small writes require 4 disk I/Os
- increases response time by factor of 2, and decreases throughput by factor of 4
- and, mirrored disk arrays just use 2 disk I/Os and hence throughput decreases by a factor of 2 only
- so applns like transaction processing can’t work with RAID lvl 5 as it is
- 3 techniques to improve small write performance
- buffering and caching
- floating parity
- parity logging
Buffering and caching
- write buffering/async writes
- acknowledge user’s writes b4 actually writing
- store in buffer
- response time improves
- throughput can be improved as
- overwrites to same data can be done w/o actually going to disk
- disk scheduler gets a larger view of I/O requests and hence can schedule effectively
- under high load, write buffer fills earlier than it empties and response time will still be 4 times worse than RAID 0
- can also gp sequential writes together => can turn small writes to larger writes
- Read Caching
- improve resp time and throughput while reading data
- assumed temporal locality
- if old data is cached, write need only 3 disk I/Os now
- if recently written parity is also cached, only 2 disk I/Os now
- parity computed over logically consecutive sectors so caching it exploits both temploral and spatial locality
- improve resp time and throughput while reading data
Parity Logging
- delay read of old parity and write of new parity
- instead of updating parity immediately, write diff b/w old and new parity known as update image to a log
- store parity update image temporarily in nonvolatile memory
- when this memory fills up, write update image yo log region on disk
- when log fills up, read parity update image in memory and add to old parity and write result to disk
- more data is transferred to and from disk but larger accesses are efficient than smaller ones
- small write overhead reduces from 4 to little more than 2 disk I/Os
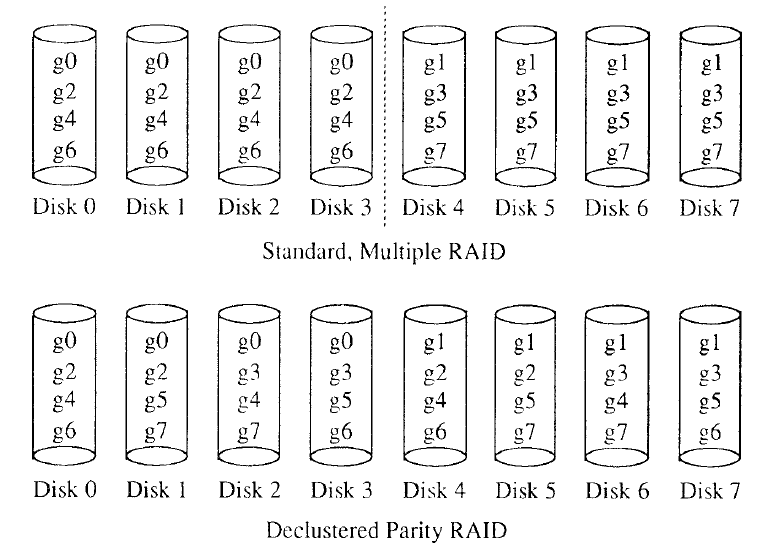
Declustered Parity
- disk failures can cause performance degradations in standard RAID level 5 disk arrays
- a workload with small reads will double effective load at nonfailed sisks due to extra disk accesses needed to reconstruct data for reads to failed disk
- though striping data across several RAIDs reduces average increase in load than RAIDs with one large parity gp, but RAID with failed disk still experiences a 100% increase in load in worst case
- Prob is although inter-RAID striping distributes load uniformly when no disk is failed. it nonuniformly distrivbutes the increased load that results from a failed disl
- small set of disks in same parity gp as failed sisk bear entire weight of increased load
- declustered-parity RAID solves this prob by distributing load uniformly over all disks
- Disadvantages?
- less reliable
- any 2 disks failures will result in data loss since each pair of disks has a parity gp in common
- complex parity gps could disrupt sequential placement of data across the disks
- less reliable
Exploiting on-line spare disks
- on-line spare disks allow reconstruction of failed disks to start immediately reducing the window of vulnerability during which an additional disk failure would result in data loss
- but they are idle most of time and do not contribute to normal operations
- 2 techniques can be used to exploit them to enhance performance during normal ops
- distributed sparing

- distribute capacity of spare disk across all disks in array
- instead of N data disks and 1 spare disks, u have N+1 data disks each having 1/(N+1)th spare capacity
- when a disk fails its blocks are constructed on correspondig spare blocks
- disadvantages?
- reconstructed data must eventually be copied onto a permanent replacement of failed disk, but copying can be done leisurely and hence not much affect on performance
- reconstructed data is distributed across many disks whereas it was with single disk formerly, so original darta placement is disturbed
- parity sparing

- it uses spare capacity to store parity information
- second parity can be used to partition disk array logically into two separate disk arrays
- and it can be used to implement P+Q redundancy
- distributed sparing
Data Striping in Disk Arrays
- deciding striping size requires to overcome 2 conflicting goals
- maximizing amount of data a disk transfers with each logical I/O
- positioning time is wasted work so maximizing amount of useful work done b/w two positionings is beneficial
- utilizing all disks in an I/O
- Idle times are also wasted time
- ensuring this means data is spread widely among more disks and hence each disk transfers less data in one logical I/O
- finding balance between two is tradeoff in deciding data distribution and is workload dependent
- maximizing amount of data a disk transfers with each logical I/O
- If concurrency of workload is known, formula for striping unit providing 95% of maximum throughput possible for any particular request distribution
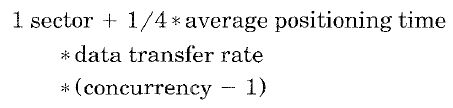
- avg positioning time = avg seek time + avg rotational delay
- small concurrency give smaller striping unit allowing all acesses to utilize all disks
- large concurrency gives large striping unit and more different accesses can be serviced in parallel
- if nothing is known about concurrency
